Methodology
The introduction leaves many questions unanswered, primarily about methodology. We shall address them as follows:
- What are the basic assumptions behind this methodology?
- How is the REScore for each voter calculated?
- Are there alternative calculations that should be considered?
- How are Legislative Power Scores for individual voters used to generate the Legislative Power Index?
- How are voting preferences simulated, given the lack of such data for Canadian elections?
Assumptions
The core assumptions are that each voter should have a representative1 they can turn to with their policy concerns and that equal representation is better than unequal representation.
We assume that voting uses a ranked ballot (not necessarily exhaustive) where the maximum number of preferences can be specified. Single Member Plurality simply sets the maximum number of preferences to one. Using a common ballot format allows us to more easily compare several different electoral systems, although modelling ranked ballots in the Canadian context is difficult.
We assume that each voter ranks their ballot sincerely and that a higher-ranked candidate will represent the voter better than a lower-ranked candidate.
Calculating the Legislative Power Score for each voter
Calculating the Legislative Power Score (LPS) for a voter involves three steps:
- Calculate the base score using the voter’s ballot
- Adjust the base score to account for the number of voters represented
- Normalize the scores so the average score is 1
This basic framework allows for a number of variations. We’ll start with the simplest, a FPTP election.
FPTP Example
The base score will be 1 if the voter’s choice was elected and 0 otherwise.
Suppose an average MP has 50,000 people vote for them. An MP that is elected with only 25,000 votes (perhaps because the riding is small to begin with or it was a tight multi-way race) will split their legislative power among fewer voters and thus provide them with better representation. In this case we multiply the base score by 50,000/25,000 or 2.
On the other hand, suppose the MP’s legislative power is split between 100,000 voters while the typical MP’s legislative power is split between 50,000 voters. Each of those voters will receive less attention and so we multiply the base score by 50,000/100,000 or 1/2.
Finally, we find the average of all the scores and divide each score by that average. The result is an average score of 1 making variations (different voting systems, different ways of calculating the base score) easier to compare.
There are some differences between provinces that are embedded in Canada’s Constitution. For that reason, the average votes per MP are taken at the provincial level.
Ranked Ballot Example
The situation is a little bit more complex for a ranked ballot, for example in an STV election.
The voter may be represented by multiple MPs and it could be that the voter’s first choice was
not elected.
In this situation we calculate the base score for each candidate the voter voted for who was elected. Those scores are weighted according to the voter’s preferences and then added together.
For example, assume the following:
- a voter voted for candidates A, B, C, D, and E (in that order of preference),
- candidates B and D were actually elected with 60,000 and 40,000 votes, respectively,
- we weight a first preference winner with 1, second preference with 0.8, third preference with 0.6, etc.
- that the average MP represents 50,000 voters
Then this voter’s adjusted base score would be .8*50,000/60,000 + .4*50,000/40,000 = 0.666 + 0.5 = 1.166.
Finally, that adjusted base score would then be divided by the average of all the scores.
Older explanation follows
This calculation involves two steps. The first step is to apply a utility function, u(b,e,w) to each voter. The utility function consumes
- a ranked ballot, b,
- the set of elected candidates, e, that could have appeared on the voter’s ballot (i.e. that the voter could have voted for),
- and a vector of weights, w.
It produces a non-negative number where 0.0 indicates no substantive representation for that voter and larger numbers indicate better representation. This function is discussed in more depth in a moment.
The second step is to normalize these values so that 1.0 is the average representation. 0.0 still means no representation and larger values still mean better representation. The REScore equation for the ith voter is
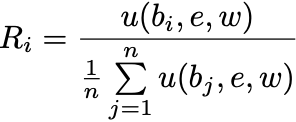
where:
- n is the number of voters
- bi is the ballot for the ith voter.
That is, it’s simply the voter’s utility function divided by the average of the function applied to all voters.
There are many possible implementations of the utility function, u(b,e,w). The ones we have considered sum the contributions from each elected candidate on the voter’s ballot, weighted according to how they were ranked.
Mathematically, the utility function is implemented as follows
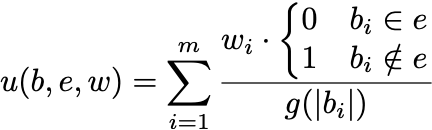
where
- b is the ranked ballot cast by the voter and bi is the candidate ranked as the _i_th preference. Note that this use of bi is different than the one above. [Suggestions?]
- e is the set of elected candidates that could have appeared on b.
- w is a vector of weights in [0, 1] giving the contribution of each preference.
- m is the number of preferences expressed on ballot b.
- g(|bi|) is a function on the number of votes received by candidate bi.
In plain English, we sum the contribution of each successful candidate on the voter’s ballot. Each of those contributions is weighted, presumably with the first preference being weighted more heavily than the second preference, which is weighted more heavily than the third. Finally, the contribution is divided by the number of voters that candidate represents. Representing fewer voters means the candidate can give each one more attention and thus represent them better.2 Most of our work to date has divided by the square root of the number of votes.
Calculating the Representation Equity Index for an election
The Representation Equity Index is a single number that captures the equity (or inequity) of the Representation Effectiveness Scores. It’s caculated exactly the same way as the Gini Coeffiencent that is commonly used to represent income inequality.
Simulating voter preferences
Simulating voter preferences is the same as generating a ranked ballot for each voter. This problem is discussed in the next section.
-
We distinguish between the representation work of an MP from the constituency work of an MP. The former consists of representing a voter’s policy concerns in Parliament. The latter consists of helping the voter navigate government bureaucracy. We are interested in the former and uninterested in the latter as it could be easily replaced by a non-partisan ombudsman. ↩︎
-
This is taking into account, roughly, the issues that gave rise to the “one person, one vote” Supreme Court case in the United States. ↩︎